
개발 서버에서 Spark를 사용하여 위의 파이프라인 데모를 구성했습니다.
Spark(PySpark)를 통해 특정 파일 확장자(CSV, JSON 등)를 RDB에 저장합니다.
> 샘플 파일
Postgresql_to_MariaDB
import pyspark
from pyspark.sql import SparkSession
ip = "10.65.41.141"
port = 5432
user = "isharkk"
passwd = "rplinux"
db = "testt"
sp = pyspark.sql.SparkSession \
.builder \
.config("spark.driver.extraClassPath", "/root/spark-3.2.2-bin-hadoop3/jars/postgresql-42.5.4.jar") \
.getOrCreate()
query = sp.read.format("jdbc")\
.option("url","jdbc:postgresql://10.65.41.141:5432/testt") \
.option("driver", "org.postgresql.Driver") \
.option("dbtable", "ishark.fps") \
.option("user", "isharkk") \
.option("password", "rplinux") \
.load()
query.show()
query1 = query.write.format("jdbc")\
.option("url","jdbc:mariadb://10.65.41.140:3306/test") \
.option("driver", "org.mariadb.jdbc.Driver") \
.option("dbtable", "post_spark") \
.option("user", "root") \
.option("password", " ") \
.save()> PostgreSQL 테이블
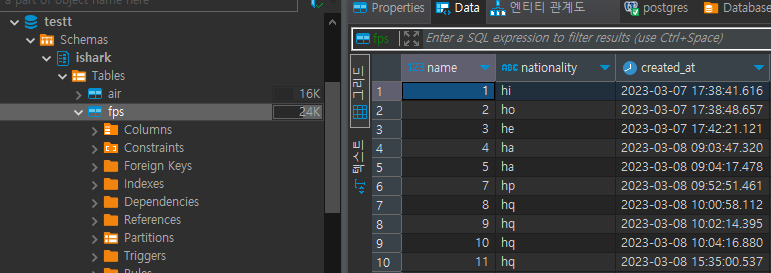
>MariaDB 테이블
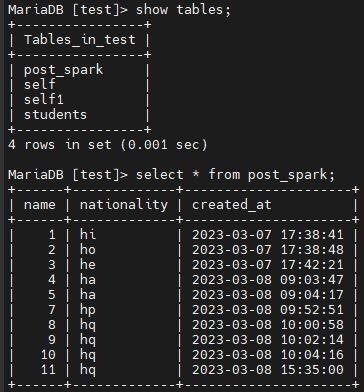
Postgresql 테이블 데이터가 정상적으로 수신되었는지 확인할 수 있습니다.